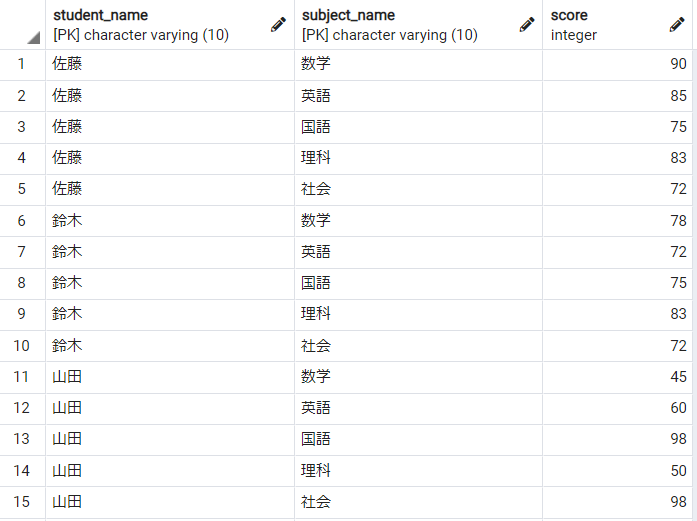
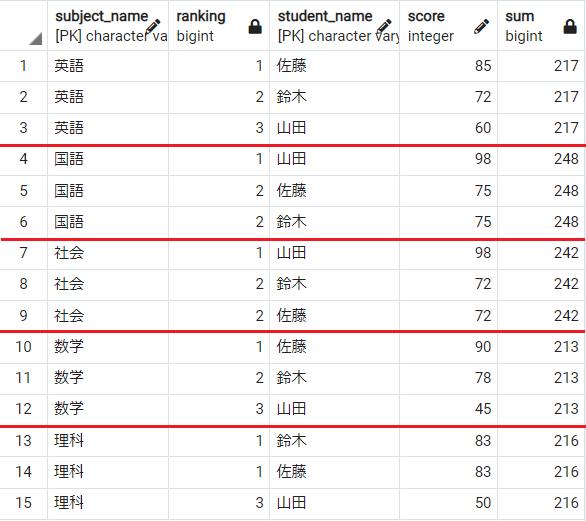
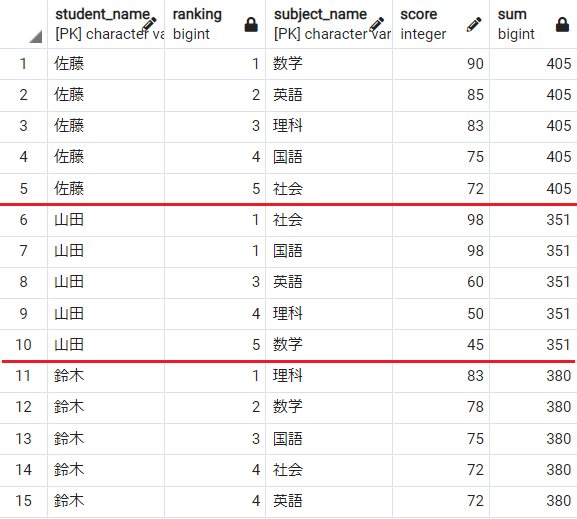
マテリアライズドビュー(マテビュー)とは
マテリアライズドビューとは、実際にデータがテーブルに格納されるビューです。
格納されたデータを取得するだけのため、ビューよりはデータ取得が高速な反面、
データは更新しないと古いままのデータになってしまうため、注意が必要です。
マテリアライズドビュー(マテビュー)を作成する
マテビューを作成する構文です。
※VIEWを作る構文に「MATERIALIZED」がつく形になります。
--マテビューを作成する構文
CREATE MATERIALIZED VIEW マテビュー名 AS
SELECT xxx , xxx, … FROM テーブル名;
マテビューにINDEXを作成する
マテビューにもテーブルと同じく、INDEXを定義することができます。
--マテビューにINDEXを定義する
CREATE UNIQUE INDEX ON マテビュー名(列1 , 列2 , ・・・);
マテビューを更新する
マテビューのデータを更新(=リフレッシュ)する方法です。
マテビューはリフレッシュ中にロックがされるため、リフレッシュが終わるまで待たされる
という欠点があります。(リフレッシュが短い場合は特に気にしなくてもいいですが)
解決するには「CONCURRENTLY」オプションをつけることで、
テーブル全体をロックすることなくマテリアライズドビューの更新が行えます。
(オプションをつけるには、INDEXか主キーが作成されている必要があります。)
--通常のリフレッシュ文
REFRESH MATERIALIZED VIEW マテビュー名;
--CONCURRENTLYをつけた方式、ただしこれにはINDEX作成が必要
REFRESH MATERIALIZED VIEW CONCURRENTLY マテビュー名;