PostgreSQLのサービス開始、停止、再起動コマンド
PostgreSQLのサービス停止・再起動コマンドを紹介します。
大きく2つの方法(① pg_ctlを使用する、② net start / stopを使用する)があり、それぞれについて説明します。②はWindowsの機能になるため、安全に停止するなら①のpg_ctlの場合がよいかと。
方法①:pg_ctlを使用
pg_ctlを使用しサービスの開始、停止、再起動を行うコマンド例です。
--PostgreSQLサービスの開始(-Dでdataフォルダを指定する)
pg_ctl.exe start -D "C:\Program Files\PostgreSQL\data"
--PostgreSQLサービスの停止
pg_ctl.exe stop -D "C:\Program Files\PostgreSQL\data"
--停止モードは3種類あり(詳細は下記参照)
pg_ctl.exe stop -m smart -D 省略
pg_ctl.exe stop -m fast -D 省略
pg_ctl.exe stop -m immediate -D 省略
--PostgreSQLサービスの再起動
pg_ctl.exe reload -D "C:\Program Files\PostgreSQL\data"
--PostgreSQLサービスの状態を確認
pg_ctl.exe status -D "C:\Program Files\PostgreSQL\data"
停止方法(smart , fast , immediate)について
「ーm」で指定できる停止方法には、smart , fast , immediateの3パターンがあります。
・smart:すべてのクライアントが切断するのを待ってからデータベースを停止
・fast:実行中のトランザクションをすべてロールバック+クライアント接続を強制的切断し、停止
・immediate は、サーバプロセスを即座に停止(DB再起動時にリカバリ処理が実行)
尚、デフォルトはfastになっています。(PostgreSQL9.5以降)
方法②:net start / stopを使用
net start / net stopを使用し、PostgreSQLのサービスを開始、終了、再起動する例です。
※ コマンドプロンプト(もしくはPowerShell)を管理者権限で実行して下さい。
管理者権限のやり方:コマンドプロンプトを右クリック > その他 > 管理者として実行
--PostgreSQLサービスの開始
net start postgresql-XXXXX
net start postgresql-x64-12 --例:PostgreSQL12の場合
--PostgreSQLサービスの停止
net stop postgresql-XXXXX
net stop postgresql-x64-12 --例:PostgreSQL12の場合
--PostgreSQLサービスを再起動する(停止 → 起動の順番に実行する)
net stop postgresql-x64-12 --例:PostgreSQL12の場合
net start postgresql-x64-12
方法②の補足:サービス名の調べ方
上で紹介した 『postgresql-x64-12』の箇所はサービス名を指定しています。
サービス名は、次の手順で確認します。
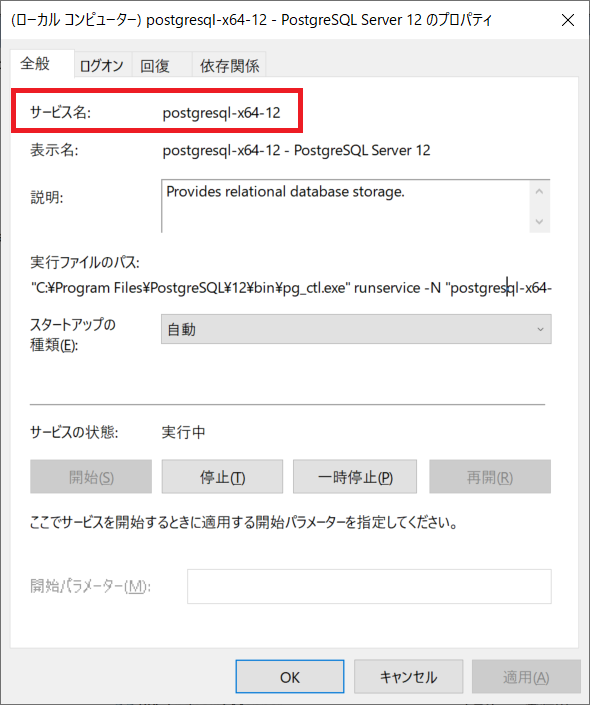
① エクスプローラー上のPCを右クリック > 管理をクリック
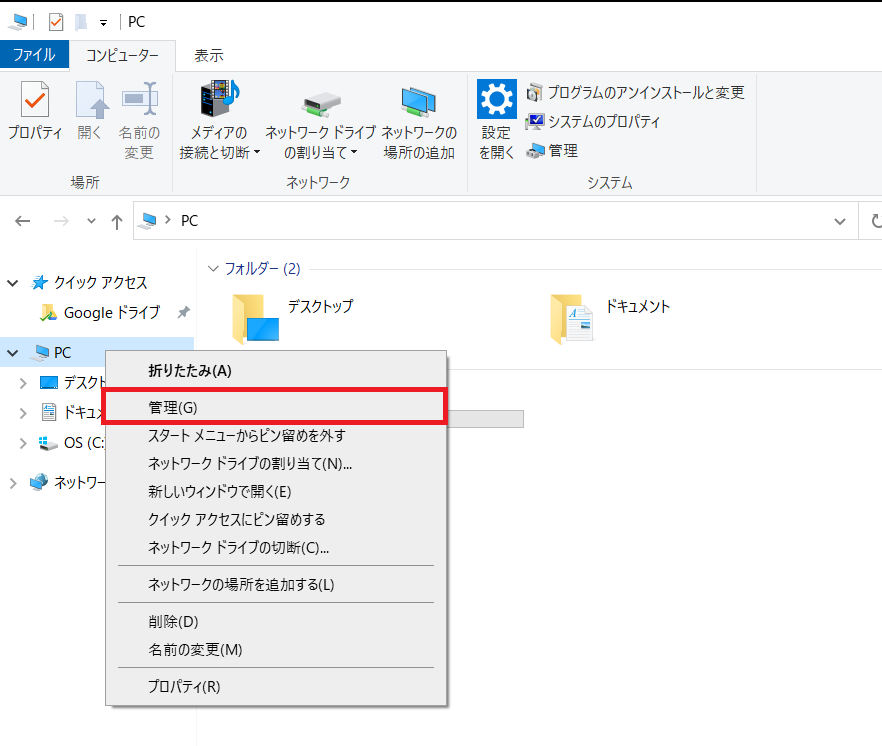
② 左赤枠内のサービスアプリケーション > サービスから
「postgresql-XXXX」で始まるサービス名を右クリック > プロパティをクリックします。
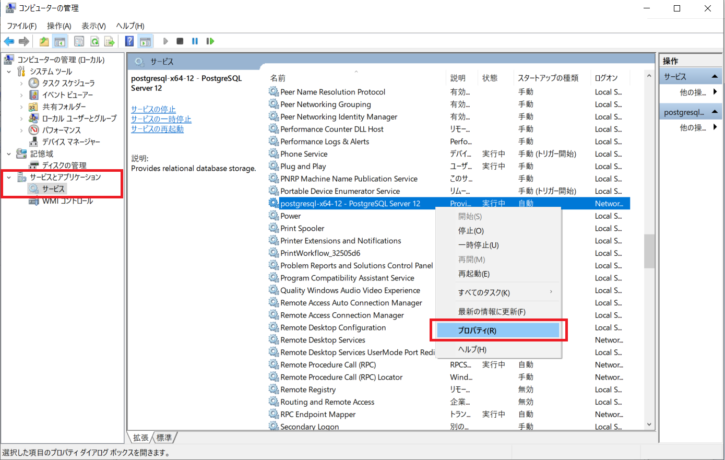
③ 左赤枠内の表示されているものがサービス名です。
この場合は、「postgresql-x64-12」がサービス名だとわかります。