pg_dumpの解説です
はじめに、PostgreSQLのpg_dumpとは、バックアップを取得するコマンドなのですが、
オプションが死ぬほど多い、サイトによっても書き方が違う等々、正直私には難しいものでした。
それでもいろいろ調べ、試行錯誤しながら理解したことを残したいと思います。
全くわからない人向けに書きますのでご理解頂ければ幸いです。
pg_dumpとは
まず、pg_dumpとはデータベースのバックアップを行うPostgreSQLのコマンドです。
pg_dumpを実行するためには、次の例のように「pg_dump」を先頭に記述し、
その後にこのような記述の形になります(サイトによっていろいろな表記がありますが)。
pg_dump XXXX XXX # いろいろな書き方あり(後述)
pg_dump --file=test.sql testdb # 例えばこんな感じ
そもそも「pg_dump」って何?どこの誰よ?というと…
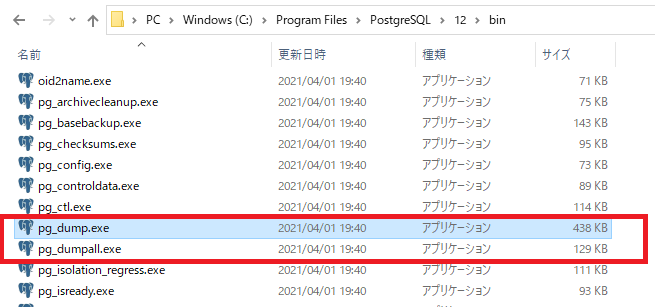
次の場所にあるのがpg_dumpの正体です。
・Windowsの場合
「C:\Program Files\PostgreSQL\XX\bin\pg_dump.exe」 ※XXはバージョン
PostgreSQLのインストール先を特に変更していなければこのパスになるはずです。
※ 画面はPostgreSQL12の場合。pg_dump.exeと同じフォルダにあります。
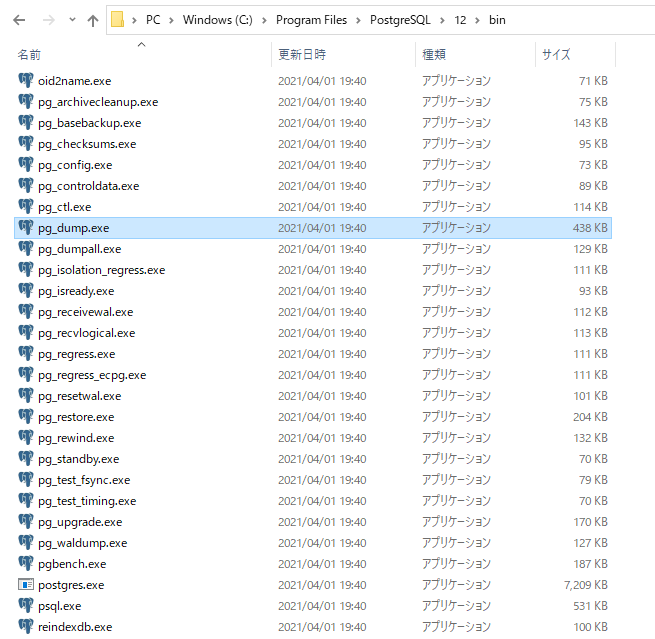
・Linux(Ubuntu Server)の場合
「/usr/bin/pg_dump」にあります。
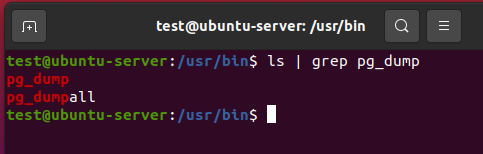
pg_dumpとpg_dumpallの違い
pg_dumpを探した時、pg_dumpallという似た名前があることに気づいたでしょうか。
pg_dumpもpg_dumpallも同じバックアップを取る時に使うものですが、目的が若干異なります。
・pg_dump … 一つのデータベースのバックアップ取得する
・pg_dumpall … すべてのデータベースのバックアップやユーザー(=ロールという)を取得する
pg_dumpは内部的にpg_dumpを複数回行っている形になります。
そのためpg_dumpのほうに焦点をあてて説明します。
補足.pg_dumpが認識されない時
pg_dumpを実行しようとした時、
「pg_dumpは、内部コマンドまたは外部コマンド、操作可能な…認識されません」
というメッセージが表示されるケースがあります。
コマンドの打ち間違いでない限り、理由はこのどちらかだと思います。
① 環境変数(Path)に設定されていない
② pg_dumpのある場所で実行していない
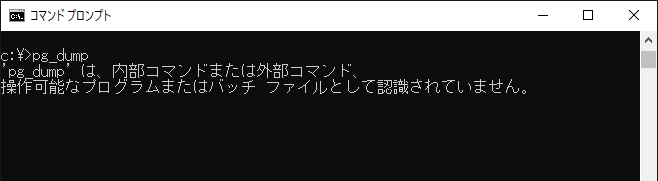
対処方法はこちらで紹介していますので、困った場合は参考にしてみて下さい。
ーーUについて
pg_dumpのコマンド解説(-Uについて)
ここからはpg_dumpのコマンドを1つ1つ解説します。
pg_dumpのコマンドの基本形は次のような形になります。
# pg_dumpのコマンドの基本形
pg_dump -U ユーザー名 --format=出力形式 --file=出力先 バックアップを取るDB名
# 実際のコマンド例
pg_dump -U postgres --format=p --file=c:\backup\test.sql testdb
(他のサイトと書き方が違くない?とか思った人がいるかもしれないですが、
少しずつ解説していきますのでお付き合いください。。)
実際のコマンド例を基にします。
「-U postgres」の箇所は、postgresユーザーで実行することを示していますが、
すでにpostgresユーザーでログインしている時は不要な(=省略可能な)箇所です。
# 実際のコマンド例
pg_dump -U postgres --format=p --file=c:\backup\test.sql testdb
# すでにログインしているときには-Uが不要
pg_dump --format=p --file=c:\backup\test.sql testdb
ーーformatについて
formatで指定できる4パターンについて
次に「--format=p」の箇所についてです。formatで指定できるのは4パターンです。
① --format=p:SQL文のテキストファイルで出力される(データも含みます)。※ p=plain
② --format=c:カスタム形式(=簡単にいうと圧縮されたバックアップファイルのこと)
③ --format=t:tar形式
④ --format=d:ディレクトリ形式(テーブル単位でのカスタム形式)
※ ①がデフォルト値(formatを指定しない場合は=pと同じ意味になります。)
※ ④のみ--jobsというオプションを使うと並列バックアップが可能
①をスクリプト形式というのに対し、②~④の形式をバイナリ形式と呼びます。
補足ですが、①はデフォルト値のため「--fomat=p」は省略できます。
②は圧縮されたバックアップファイルのため、
他の①、③と比べてもファイルのサイズがかなり小さくなります。
③のtar形式とは、ざっくりいうと複数のファイルが1つになったもののことです。
tar自体はPostgreSQL独自ではないので調べてみて下さい。
④はフォルダが作成されその中にファイルが複数出力される形になります。
※いずれの方法も後半で実行結果を紹介しています。
# ①--format=p : SQL文のテキストファイルで出力(次の2行は同じ意味)
pg_dump -U postgres --format=p --file=c:\backup\test1.sql testdb1
pg_dump -U postgres --file=c:\backup\test1.sql testdb1 # format=pは省略可
# ②--format=c : カスタム形式のファイルで出力
pg_dump -U postgres --format=c --file=C:\backup\test2.custom testdb2
# ③--format=t : tar形式
pg_dump -U postgres --format=t --file=C:\backup\test3.tar testdb3
# ④--format=d : ディレクトリ形式
pg_dump -U postgres --format=d --file=C:\backup\test4 testdb4
--formatは書き換え可能
さらに「--format=」は「-F」に書き換えが可能です。ーFはハイフンが一つのため注意。
それぞれ書き換えると次のようになります。
① --format=p = -Fp
② --format=c = -Fc
③ --format=t = -Ft
④ --format=d = -Fd
# --format=p : SQL文のテキストファイルで出力(次の3行は同じ意味)
pg_dump -U postgres --format=p --file=c:\backup\test1.sql testdb1
pg_dump -U postgres -Fp --file=c:\backup\test1.sql testdb1
pg_dump -U postgres --file=c:\backup\test1.sql testdb1 # format=pは省略可
# --format=c : カスタム形式のファイルで出力(次の2行は同じ意味)
pg_dump -U postgres --format=c --file=C:\backup\test2.custom testdb2
pg_dump -U postgres -Fc --file=C:\backup\test2.custom testdb2
# --format=t : tar形式(次の2行は同じ意味)
pg_dump -U postgres --format=t --file=C:\backup\test3.tar testdb3
pg_dump -U postgres -Ft --file=C:\backup\test3.tar testdb3
# --format=d : ディレクトリ形式(次の2行は同じ意味)
pg_dump -U postgres --format=d --file=C:\backup\test4 testdb4
pg_dump -U postgres -Fd --file=C:\backup\test4 testdb4
4パターンの出力方法の使い分け
CPUのリソースを必要としますが、圧縮された形式で取得したい、早くバックアップを
終わらせたいといった場合には、②カスタム形式または④ディレクトリ形式を選択。
特に速さ重視なら並列バックアップ可能なディレクトリ形式のほうがよいと思います。
CPUリソースを使いたくない時は、①テキスト形式または③tar形式を選択します。
一般的におすすめは②カスタム形式です。
理由は、リストア時に(テーブル単位等での展開ができる等の)柔軟性があること、
必要であればテキスト形式へ変換可能なことが挙げられています。
--fileについて
指定するファイル名
「--file=c:\backup\test.sql」の箇所ですが、フルパス、ファイル名どちらでもOKです。
フルパスでなくファイル名だけを指定すると、コマンドプロンプトで現在いるフォルダ
(カレントディレクトリ)に出力されます。
pg_dump -U postgres --format=p --file=c:\backup\test1.sql testdb1 # フルパス
pg_dump -U postgres --format=p --file=test1.sql testdb1 # ファイル名のみ
拡張子
ぶっちゃけ拡張子はなんでもいいです(たぶん)。
ただ次のようになることが多いので、合わせておいた方が無難かと。
① テキスト形式:「.sql」
② カスタム形式:「.dump」、「.custom」、「.backup」、「.dmp」
③ tar形式:拡張子をつけない、「.tar」
④ ディレクトリ形式:拡張子をつけない
実行確認
最後に4パターン(テキスト形式~ディレクトリ形式)で実行し、
どのような結果になるか簡単ですが紹介します。
テスト環境の用意
バックアップ動作確認用の環境を作成します。
余談ですがテスト環境を作成するには、pgbenchを使った便利な方法があります。
大量のテストデータを用意する場合などにも使えますので参考にしてみて下さい。
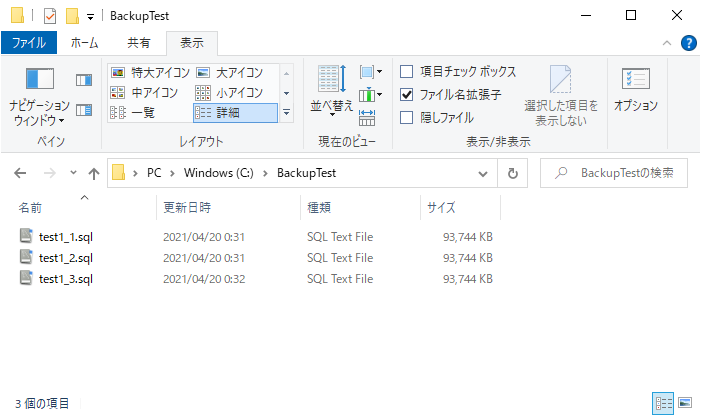
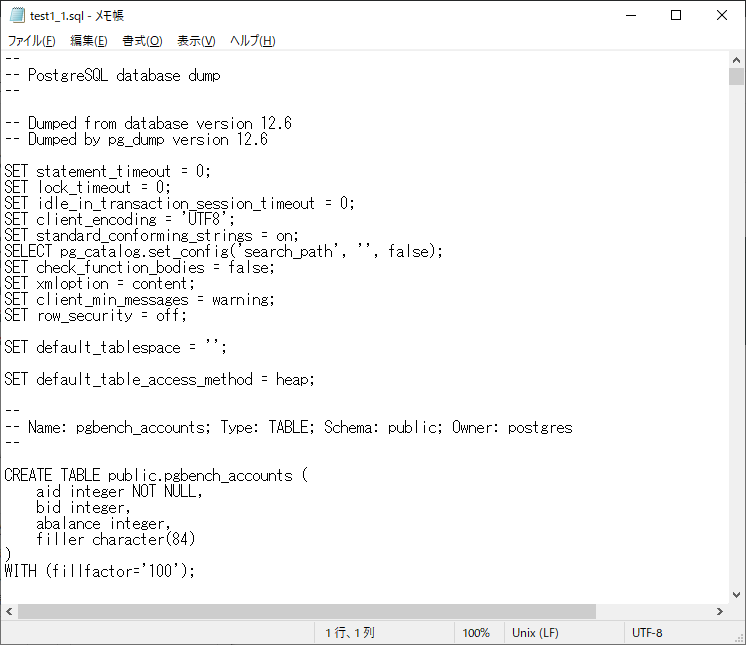
① テキスト形式でのバックアップ実行
念のため3パターンで実行
# --format=p : SQL文のテキストファイルで出力(次の3行は同じ意味)
pg_dump -U postgres --format=p --file=C:\BackupTest\test1_1.sql testdb
pg_dump -U postgres -Fp --file=C:\BackupTest\test1_2.sql testdb
pg_dump -U postgres --file=C:\BackupTest\test1_3.sql testdb
実行結果確認。3つとも問題なく実行可能。
メモ帳で開くとこんな感じ。SQLがずらずらと並びます。
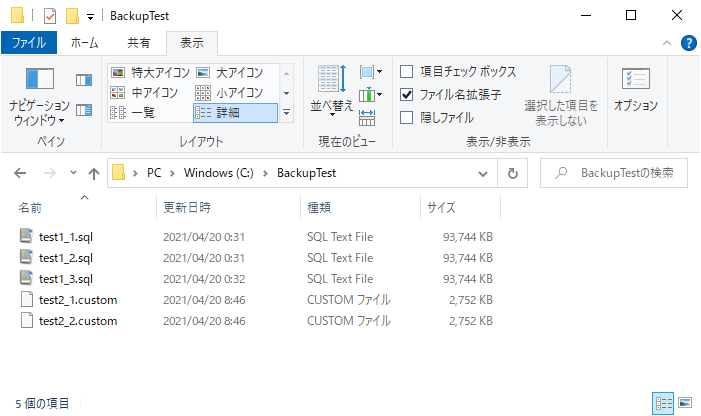
② カスタム形式
2パターンで実行
# --format=c : カスタム形式のファイルで出力(次の2行は同じ意味)
pg_dump -U postgres --format=c --file=C:\BackupTest\test2_1.custom testdb
pg_dump -U postgres -Fc --file=C:\BackupTest\test2_2.custom testdb
問題なく実行完了。
サイズはテキスト形式と比べ明らかに減っています。
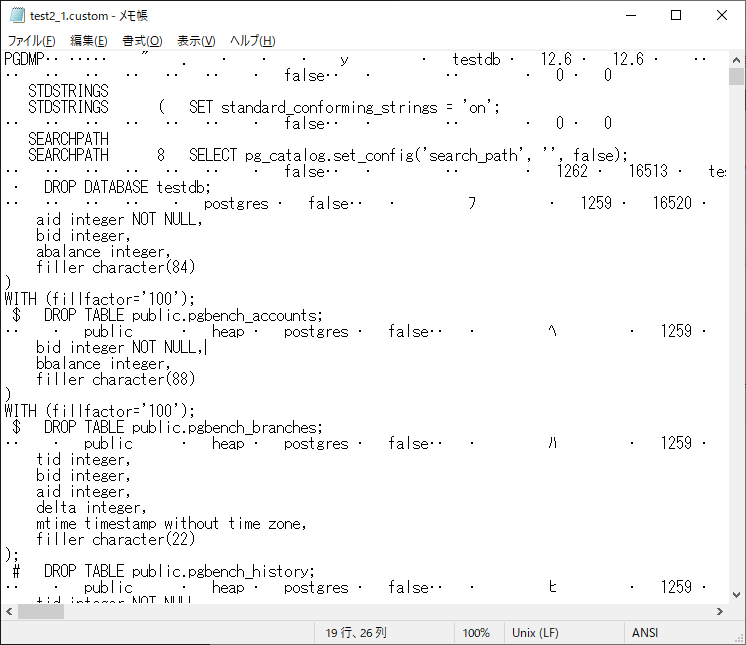
メモ帳では、よくわからない形になります。
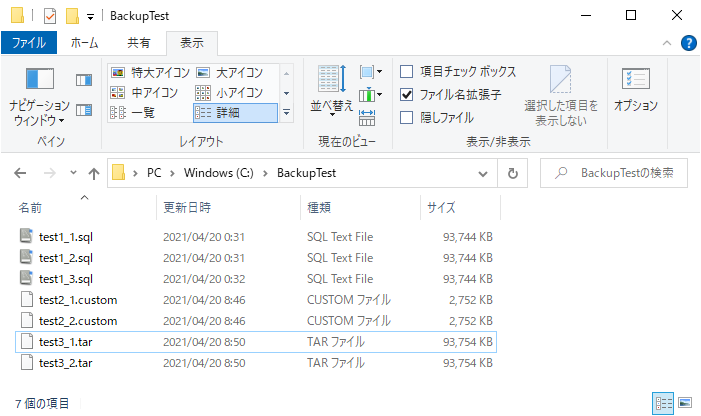
③ tar形式
2パターンで実行
# --format=t : tar形式(次の2行は同じ意味)
pg_dump -U postgres --format=t --file=C:\BackupTest\test3_1.tar testdb
pg_dump -U postgres -Ft --file=C:\BackupTest\test3_2.tar testdb
こちらも問題なく実行完了。
サイズはテキスト形式と同じくらいになりました。
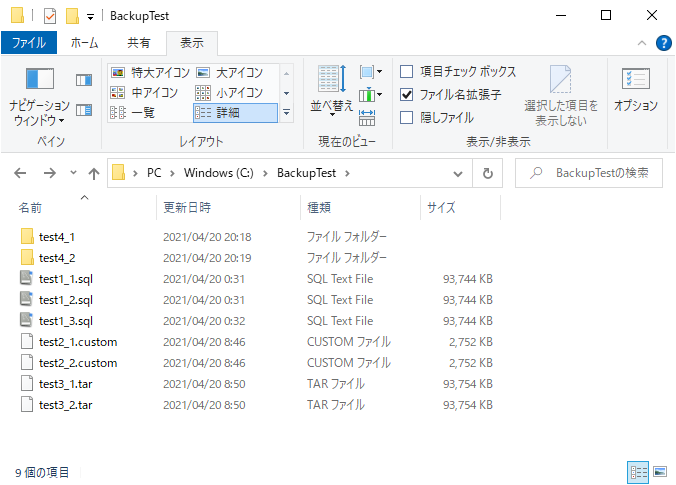
④ ディレクトリ形式
最後にディレクトリ形式です。
# --format=d : ディレクトリ形式(次の2行は同じ意味)
pg_dump -U postgres --format=d --file=C:\BackupTest\test4_1 testdb
pg_dump -U postgres -Fd --file=C:\BackupTest\test4_2 testdb
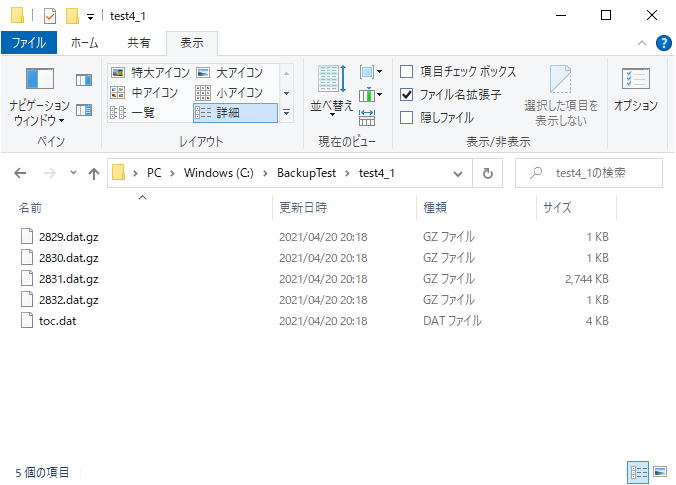
フォルダが作成され、その中にいくつかファイルができます。
フォルダの中身はこんな感じです。
以上、pg_dumpの解説でした。
少しでも参考になりましたらうれしい限りです。
リストアについて
リストアの方法についてはこちらで紹介しています。
https://postgresweb.com/post-4279