システム管理基準のありか
試験勉強にあたって「システム管理基準」がパっと見つからず困ったので、同じ人がいるかと思いリンク先共有します。
リンク先:経済産業省(「システム監査基準」及び「システム管理基準」について)
ここにありました。

試験勉強にあたって「システム管理基準」がパっと見つからず困ったので、同じ人がいるかと思いリンク先共有します。
リンク先:経済産業省(「システム監査基準」及び「システム管理基準」について)
ここにありました。
Zennでのご購入ありがとうございました。
右側の「ダウンロード」ボタンよりダウンロードしてください。
ここでは、PostgreSQLとMySQLを比較した時、「どういう場合にPostgreSQLを選択するか(またはMySQLを選択するか)」ということについて触れていきたいと思います。
まずPostgreSQLとMySQLの類似点ですが、次のようなことが挙げられます。
まぁここについては基本的なところでしょう。
・RDBMSであること
・SQLが使えること
・JSONが使えること
MySQLと比べた時、PostgreSQLの特徴は次の点が考えられます。
① パフォーマンスとスケーラビリティの機能がある
② 複数のデータタイプにまたがる広範囲のデータ分析の機能がある
③ MVCC(多版型同時実行制御)により適切な操作と読み取りの同時発生を可能にする
④ 高可用性
一方MySQLは次の点が考えられます。
① 使いやすく非常に高速(特にWebアプリケーションで使用される)
② 通常、(エンタープライズアプリケーションと同じレベルのパフォーマンスを必要としない)小規模なウェブアプリケーションに使用される
③ 優れたパフォーマンスをもたらす独自のメモリキャッシュ
お互いの特徴を踏まえるとPostgreSQLを選択するケースは次のケースです。
①複雑なクエリや、複数のデータ型を処理する必要がある時
②すぐれた同時実行制御を備えたデータベースが必要な場合
③エンタープライズアプリケーション用のデータベースが必要な場合
MySQLを選択するケースは次のケースです。
小規模から中規模のウェブアプリケーション用で、高速かつ使いやすいデータベースが必要な場合
以上です。DBMSの選択をする際のご参考になれば幸いです。
時系列データベースとは、時系列データに最適化されたデータベースのことです。
時系列データとは、タイムスタンプを持った複数の値の集まりです。タイムスタンプは一定間隔で連続的な値をとります。
例:株価データ、気象データ、売上データ、アクセス数など
時系列データベースに求められるものとして、「時間に伴う大量のデータを扱うことができる書き込み能力」、「データの分析能力」、「データを効率よく保存する能力」が求められます。
時系列データベース製品の人気ランキングは次のとおりのなっています(2022年12月時点)。
1.Influx DB(インフラックスDB)
2.Kdb+(ケーディービープラス)
3.Graphite(グラファイト)
4.Prometheus(プロメテウス)
5.TimescaleDB(タイムスケールDB)
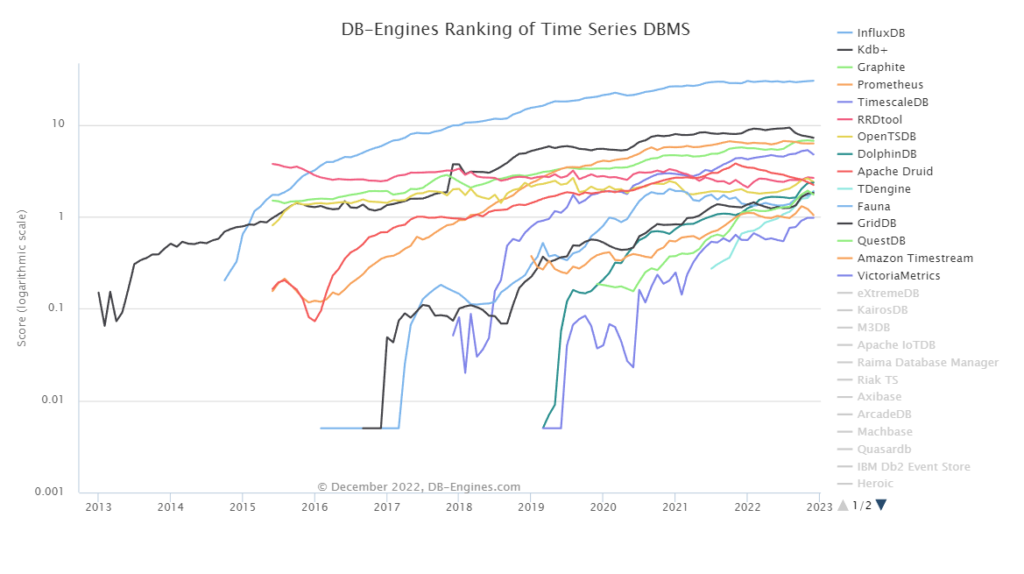
DB-Engines Ranking - Trend of Time Series DBMS Popularity
TimescaleDBとは、アメリカのTimescale社が開発している時系列データベースで、PostgreSQLの拡張機能として実装されました。
PostgreSQLの拡張として実装されていることにより、次のような特徴があります。
・SQLやPostgreSQL用のアプリケーションがそのまま使用可能
・PostgreSQLの安定感・信頼感を享受できる
・データ量が増えても安定して高速に書き込みが可能
ライセンスTimescaleDBは大部分はApache License2.0というオープンソースのライセンスのため、自由に使用可能です。
しかし一部の機能は、Timescale Licenseといったライセンス形式(TimescaleDBをデータベースサービスとして提供しなければ自由に使用可能)のため注意が必要です。なお、個人使用なら自由に使ってよいことになります。
TimescaleDBとPostgreSQLのバージョンには対応関係があります。
それぞれの対応にあったバージョンでなければならないため、注意してください。
|
TimescaleDBバージョン |
PostgreSQLバージョン |
| 2.5以降 | 12、13、14 |
| 2.4 | 12、13 |
| 2.1、2.2、2.3 | 11、12、13 |
| 2.0 | 11、12、 |
| 1.7 | 9.6、10、11、12 |
PostgreSQL 15が少し前にリリースされ、Oracleからの移行を考えたOracle互換関数など、個人的に面白いなと感じた機能も追加されていました。そのPostgreSQL 15の新機能や変更点を3つの面でまとめました。
1.SQL機能追加
2.性能改善
3.運用管理
それぞれについて解説・まとめをしていきます。
※ ここに記載する内容は、ほぼ次の動画を簡易的にまとめたものになります。動画にはここでは取り上げていない非互換の変更点なども紹介されています。是非動画をご参照ください(とても聞きやすくわかりやすい動画でした)。
① SQL構文(MERGE文)が追加されました
SQL標準機能でOracle、SQL Serverにもある構文、MERGE文が追加されました。
② 論理レプリケーションの機能が追加されました
・ 行フィルタ、列フィルタが可能になりました。
・ スキーマ単位でテーブルを一括指定できるようになりました。(従来はDB単位、テーブル単位のみ)
・ 論理レプリケーションでエラーが発生した際、サブスクリプションを無効にする(同じ原因のエラーが繰り返されログが圧迫するのを防ぐ、エラー原因そのものを解決するわけではない)
③ 正規表現の関数がたくさん追加されました
元々正規表現の関数群はあったが、Oracleと同じ書き方で書けるという機能が追加されました(Oracleから移植するニーズに対応)。
④ ビューに属性が追加
ビューに「security_invoker」という属性が追加されました。これによりビューを呼び出したユーザーの権限でビューのSELECT文を実行出来るようになりました。(テーブルに細かな権限設定をしても、ビューを経由されると単一ロールからのアクセスになってしまうと都合が悪いことがあったため)
① 外部ソートのアルゴリズムが変更されました
PostgreSQLでソートする際には2つの方式「インメモリソート」「外部ソート」があります。その外部ソートのアルゴリズムが現代的でないという意見から「多層マージソート」から「K-way Mergesort」に変更されました。
インメモリソート…work_memサイズ内のメモリで処理できる場合。アルゴリズム:クイックソート
外部ソート…大規模ソートの場合、一時ファイルを使って実行
② ウインドウ関数のプランが改善されました
ウインドウ関数のうち、row_number()、rank()、count()で性能向上となりました。
③ psqlの\copy命令で性能が改善されました
データを1行ずつ送出→複数行をまとめて送出するように変更。得に列の少ないテーブルの「\copy FROM」で効果がある模様。
④ Zstandard圧縮をサポートするようになりました
Zstandardは最近の圧縮方式。WAL圧縮と、ベースバックアップに利用できます。
① JSON形式のログがサポートされるようになりました。
CSV形式のログに加えて、JSON形式のログが出力できるようになりました。
② モニタリング用のビュー、関数が追加されました
pg_ident.confのファイル内容を見るビュー(pg_ident_file_mappings)などが追加されました。
③ 実行時の統計情報が共有メモリで管理するように変わりました
実行時統計情報(各テーブルの各種アクセス数 等々)は、従来ファイルに書き出していましたが、共有メモ上で管理して高速化に貢献。
④ WALのアーカイブ(更新ログ)
WALのアーカイブ処理を行うモジュールを処理可能になりました(従来はコマンドを記述する方式)。
⑤ モジュールによるベースバックアップが可能になりました
pg_basebackup(指定サーバーのバイナリバックアップを取得するコマンド)が、今までは実行したところのローカルになっていましたが、サーバー内のディレクトリも指定できるようになりました。
PostgreSQL13は変更が少なめのメジャーリリースとなっており、非互換が少なくアップグレードしやすいものとなっているようです。
以下の点、それぞれについて解説・まとめをしていきます。
1.新機能(SQL)
2.性能向上
3.運用管理
※ ここに記載する内容は、ほぼ次の動画を簡易的にまとめたものになります。詳細を知りたい方は、次の動画を是非ご参照ください(とても聞きやすくわかりやすい動画でおすすめです)。
・FETCH FIRST … WITH TIE
PostgreSQLでは、データの先頭何行だけを表示するのに「limit句」を使用する方法と、「FETCH FIRST」を使用する方法があります。その「FETCH FIRST」という構文に「WITH TIE」をつけて同じ順位(=タイ)のものも表示するように対応されました。(SQL標準の機能でしたが、PostgreSQLは組み込まれていなかったため今回追加となりました。)
・JSON Pathのdatetime()メソッド追加
JSON Pathとは、JSONのデータ型に対して中身を検索したり、加工できる機能です。今回、datetime()というJSON PATHの中で使えるメソッドが追加されました。datetime()を使用することで、日付時刻データを文字列ではなく、ちゃんと日付時刻として評価できるようになりました。
・パーティションテーブル関連の各種拡張
・ロジカルレプリケーション(テーブル単位でレプリケーションをする機能)にパーティションテーブルが追加されました。
・パーティションテーブル同士の結合が改良されました。
・パーティションテーブルに行単位のBEFOREトリガが対応されました。
・Btreeインデックスの性能向上
インデックスのデータ格納時、以前までは同じ値でも複数エントリー(=複数の格納場所)に格納していました。今回からは、同じキー値の値の場合は、1つのエントリーだけに保存されることになり、格納サイズが減る反面、処理オーバーヘッドが(若干)増えるようになりました。ただし、重複排除が効かない条件が一部のあります。この機能はデフォルトでONとなっていますが、CREATE INDEX時に明示的にOFFにすることも可能。
・インクリメンタルソートが追加
データを並び替える際の新しいアルゴリズムが追加されました。クエリを投げる時、従来まではすでにソートキーでソートされている物も改めてソートしなおし実行していましたが、今回からはすでにソートされているキーは考慮した上で(再度ソートすることなく)実行できるようになりました。デフォルトでON。
・ストレージハッシュ集約が追加
ハッシュ集約の方法について、従来まではGroupAggregateとHashAggregateという二つの方法がありました。今回、その2つの中間くらいに位置したものが1つ追加され全部で3つとなりました。
・並列VACUUM機能の追加
テーブルに対してバキュームを行った場合、テーブル+そのインデックスに対してバキューム処理が行われます。並列バキュームではテーブル+その各インデックスに対して並列でバキューム処理が行われるようになりました。
・進捗レポート対応拡張
従来ではVACUUM、CLUSTER、VACUUM FULL、CREATE INDEX、REINDEXに対して、「SQL実行している処理がどこまで進んでいるか」というのをビューで見ることができていました。その進捗で見る項目にpg_basebackup、ANALYZEコマンドが追加されました。
・接続認証の拡張
・クライアント側でチャンネルバインディングが必須に指定できるようになりました。チャンネルバインディング中間者攻撃を防ぐ機能です。
・SSL/TLSのプロトコルのバージョンを最小でいくつ、最大でいくつと指定できるようになりました。
・クライアント証明書のパスワードの指定ができるようになりました
・pgbenchの拡張
・パーティションテーブルの生成が可能になりました。
・サーバー側でデータが作成できるようになりました。
・データ生成時にフェース毎にどれだけ時間がかかったか表示できるようになりました。
・pg_rewindの改良(レプリケーション時の巻き戻し機能)
・クラッシュリカバリが自動で実行されるようになりました。
・ソースサーバーに追随するスタンバイの設定を自動で作成するようになりました。
・WALアーカイブ適用
・pg_verifybackupコマンドの追加
新しい運用管理コマンド(バックアップデータを検証する機能)が追加されました。
・その他の運用コマンド拡張
・reindexdbコマンドに--jobs対応(複数並列が可能に)
・pg_dumpが外部テーブルに含まれるデータも内容をダンプに入ることができるようになりました。
・EXTENSIONにtrustedなという概念が加わりました。
PostgreSQL 14の新機能や変更点を4つの面でまとめました。
1.性能向上
2.新機能(SQL)
3.運用管理
4.その他
それぞれについて解説・まとめをしていきます。
※ ここに記載する内容は、ほぼ次の動画を簡易的にまとめたものになります。詳細を知りたい方は、次の動画を是非ご参照ください(とてもわかりやすい動画でした)。
まず性能の向上面について。
① Btree Indexの改善
PostgreSQLは追記型のデータベースのため、更新を繰り返すとデータ量が肥大化していきます。これはテーブル本体だけでなく、インデックスも同様です。そのインデックスの更新時に不要なデータを整理する処理が入り、データの肥大化を防ぐことができるようになりました。
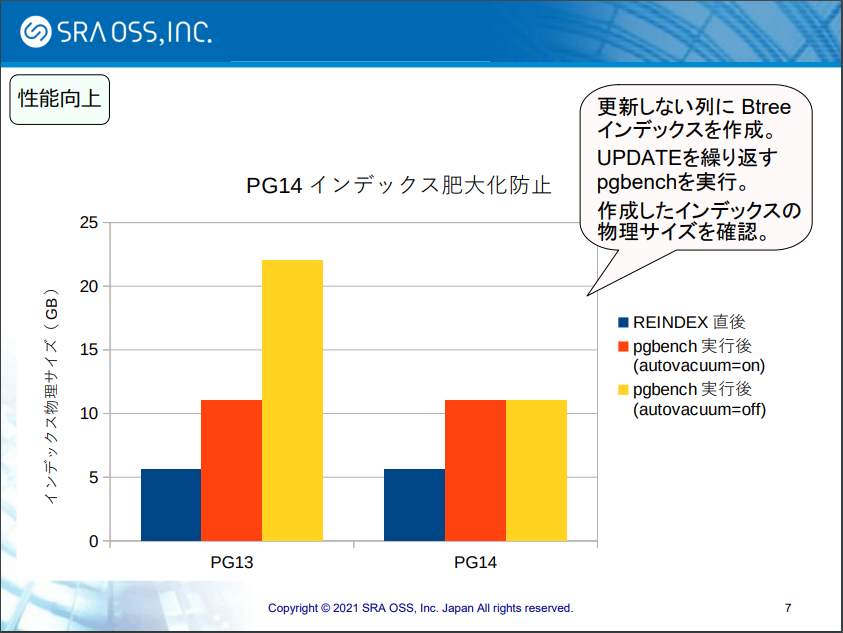
SRA OSS - 「PostgreSQL 14 新機能検証結果報告」
② 式の拡張統計という機能が追加
PostgreSQLは、プランナの統計情報(このテーブルにはこんな情報が入っているよ)を参考にSQLの実行方法を決めています。そして、その統計情報に「こういう情報も取っておいてください」と追加できる「CREATE STATISTICS」という命令があり、そこに「式に関する統計情報」を追加できるようになりました。
通常、WHERE文に式が書かれている場合、プランナは式の結果がどうなるかはわからないので、プランナ音行数予測というものはあてにならない。そのため、「この箇所は正確に行数予測しよいプランを作ってほしい」という場合に使うものとなっています。
③ LZ4によるデータ圧縮技術
PostgreSQLでは可変長データは、暗黙的にデータ圧縮がされています(1レコード2KB超の場合)。そのアルゴリズムは「pglz」というものが採用されていますが、「LZ4」という圧縮アルゴリズムも選択可能になりました。列単位で設定可能。
※設定値は「default_toast_compression」
SRA OSSの検証結果によると「2つの圧縮どちらも大差はない」とのことです。検索速度としては「lz4」が良い、圧縮率としては「pglz」がよいと出ましたが、大きな差はなかった様子。またデータ形式によっては、結果もこうなるとは言い切れないとのことです。
④ postgres_fdw改善
外部テーブルに対して、3つの機能(外部テーブルのTRUNCATE、外部テーブルの非同期スキャン、外部テーブルの一括挿入)が追加されました。外部テーブルというのは、他のデータベースのテーブルを、自分のデータベースのテーブルかのように扱うものです。
⑤ ロジカルレプリケーション改善
いくつかの機能が追加されました。
従来ロジカルレプリケーション(行、テーブル単位)では、コミット実行後に相手側に情報が送られるという挙動でしたが、「ストリーム送信」というコミット前に送出しSUB側に蓄積、コミットを受けて適用するという流れにすることができるようになりました。その他、初期同期トランザクションの巨大化を防ぐために複数トランザクションにする、バイナリ転送モード(性能向上目的)が可能などが挙げられます。
⑥ パラレルクエリ改善
パラレルシーケンシャルスキャン(=大きなシーケンシャルスキャンを複数のパラレルワーカーに分けて処理をすること)が、従来1ブロックずつ処理していたものを、複数ブロックずつ処理するように変更されました。その他、これまでパラレル対応していなかった部分が対応されました(RETURN QUERY、REFRESH MATERIALIZED VIEW)。
① マルチ範囲型
データ型に「マルチ範囲型」が増えました。範囲型は前からありましたが、それが複数連なったイメージです。範囲型同様にGiSTインデックスが使用できます。
② SEARCH / CYCLE句
WITH RECURSIVE構文(CTE再起問合せ)に、新しいオプションが加わりました。1.幅優先探索/深さ優先探索を指定できるようになる、2.循環参照の検出ができるようになる、また循環参照での検索停止ができるようになりました、3.再起検索の経路データを自分で作らなくてもよくなりました。※動画にSQL実例あり
③ 添え字構文
添え字構文が配列にしか使えなかったが、hstore型、jsonb型でも使用可能になりました。
① セッション制御機能
セッション制御機能がいくつか追加されました。1つ目として、長期のアイドルセッションを切断できるようになりました(パラメータ:idle_sesson_timeout)。2つ目にクライアント側の切断を早期検知できるようになりました。従来では重いSQLをクライアントが実行し、結果が返ってくる前にクライアント側のプロセスが終了・切断した場合、サーバーは時間のかかるSQLを実行しそれを返そうとした時にエラーを演出していていました(ここでようやく知ることができていた)が、機能が有効になっていると、サーバー側でSQL実行中でもクライアントの切断を検出して、SQL実行を中断することが可能になります。
②新システムロール
新しいシステムロールが追加されました。
・ pg_read_all_data … 全てのデータを参照だけできる
・ pg_write_all_data … 全てのデータを更新だけできる
・ pg_database_owner … 暗黙に現在のデータベース所有者をメンバとしているロール
※「pg_write_all_data」だけ付与するというより、「pg_read_all_data」とセットにし、Read/Writeを付与するための要素として「pg_write_all_data」があると考えると理解しやすいでしょう。
③ 実行時統計情報の追加
実行時統計情報がいくつか追加されました
・ pg_stat_progress_copyビュー … copyコマンドの進捗状況が確認できる
・ pg_stat_walビュー … WAL書き出し情報
・ pg_stat_replication_slotsビュー … ロジカルレプリケーションの統計情報
④ pg_amcheckコマンドの追加
テーブル、インデックスの内部データ構造を検査し、データが壊れていないかを調べるコマンドです。ここで検査するのは論理的なデータの整合性が正しいか(リンクが正しいかなど)を確認することであり、値自体が変わっている等のチェックには使えません。
⑤ pg_rewind拡張
pg_rewindコマンドが拡張されました。pg_rewindとは「walを巻き戻すツール」です。レプリケーションを行ったりクラッシュでリカバリをすると、WAL(Write Ahead Log)を適用するということを行います(プライマリのWALをスタンバイに適用することでデータを同じにする)。その適用したものを元にもどすのがpg_rewindです。従来ではスタンバイをターゲットにした巻き戻しに対応していなませんでしたが、今回から対応可能になりました。
・pg_hba.confの「clientcert=1」という記法が廃止
・V2プロトコル廃止(プロトコル:クライアントとサーバーの通信プロトコル)
・後置単項演算子(こうちたんこうえんざんし)の廃止
・EXTRACTの戻り値がfloat8型(浮動小数点)からnumeric型に・pg_standby廃止
VLCメディアプレイヤーでキーボードの「→」、「←」を押したときに、デフォルトであれば10秒進む・10秒戻るとなっていますが、この秒数を変更する手順する手順を紹介します。
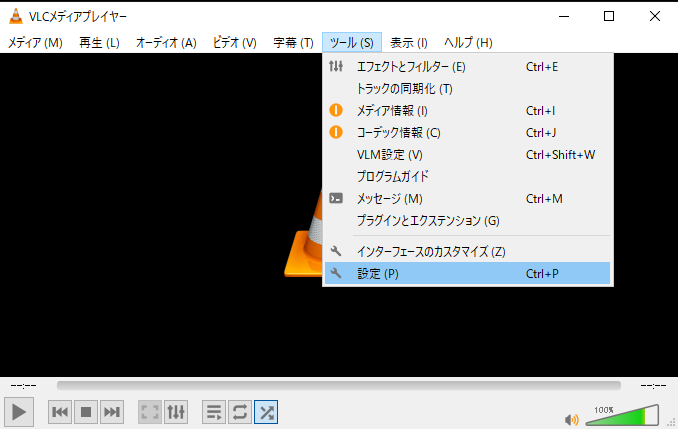
① VLCメディアプレイヤーを開き、上部メニュー>ツール>設定
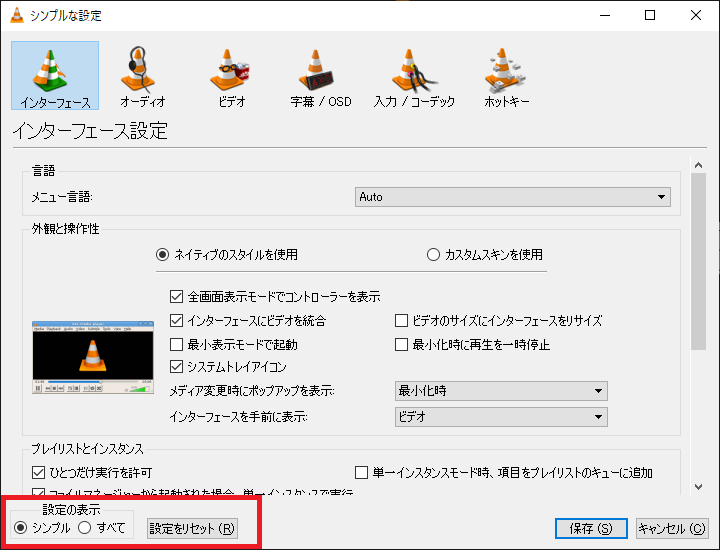
② 左下の「設定の表示」を「すべて」に変更する
③ 左のメニューで「ホットキー設定」を選択 > 右下の「ジャンプする長さ」で「少し戻ったり、進んだりする長さ」の秒数を変更し、右下の保存を押す。※画面は5秒に変更
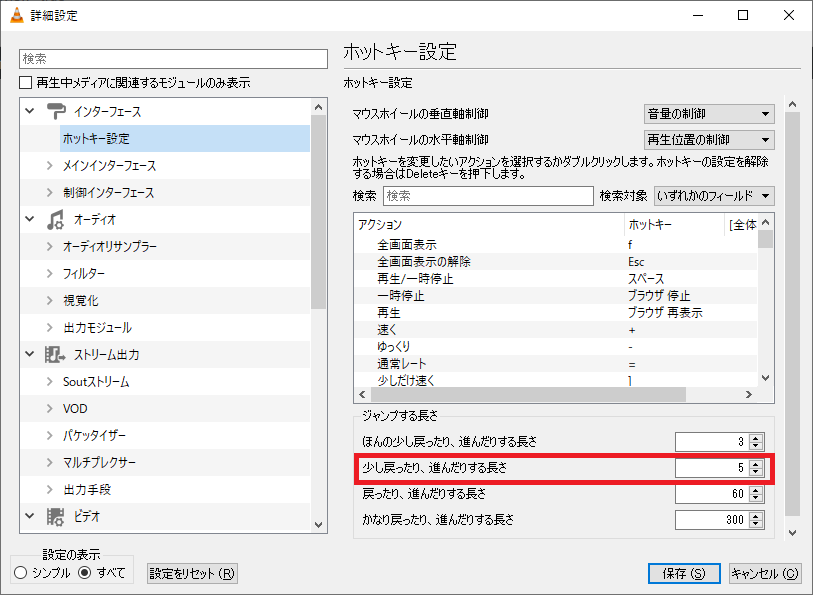
手順は以上となります。
ちなみに、上の「ジャンプする長さ」の違いは、ショートカットキーの違いです。
ほんの少し戻ったり、進んだりする長さ … Shift + → 、 Shift + ←
少し戻ったり、進んだりする長さ … → 、 ←
戻ったり、進んだりする長さ … Ctrl + → 、 Ctrl + ←
かなり戻ったり、進んだりする長さ … Ctrl + Alt + → 、 Ctrl + Alt + ←
G検定の履歴書・職務経歴書への書き方です。※E検定は読み替えをお願いします。
■履歴書
①令和X年 XX月 G検定(一般社団法人日本ディープラーニング協会)
②令和X年 XX月 一般社団法人日本ディープラーニング協会 G検定
③令和X年 XX月 JDLA Deep Learning for GENERAL 20XX #X
■職務経歴書
①G検定(20XX年XX月)
②一般社団法人日本ディープラーニング協会 G検定(20XX年XX月)
③JDLA Deep Learning for GENERAL 20XX #X(20XX年XX月)
私は両方②にしました(これでツッコミはなかったです)。
正しく書くなら、「JDLA Deep Learning for GENERAL 20XX #X」のような書き方が良いと思いますが、ぱっとわかる②の方が見た目が良いと思ったので。※名称よりも、「この資格はどんな資格なのか」「なぜこれを取得しようと思ったのか」の答えは用意しておきましょう。
あと、G検定は有効期限が設定されていませんのでご安心を。
※ どんな資格なのか?⇒JDLAのサイトにはこうありました。
『ディープラーニングの基礎知識を有し、適切な活用方針を決定して、事業活用する能力や知識を有しているかを検定する』
こちらも見て頂けるとうれしいです。
基本情報技術者試験の通年試験化に関して、現行との違い等をまとめました。
新しい方式での試験は2023年4月から開始する予定のためご注意ください。
■変更点まとめ
・試験が随時受験できるようなる(今までは一定期間中のみ)
・午前試験免除制度は継続(科目A試験免除制度という名前に)
・午前問題は問題数減+時間も短縮されるが、問題内容の変更はなし
・午後問題が情報セキュリティ、データ構造及びアルゴリズム(擬似言語)の二つの分野を中心にした構成に変更される
・個別プログラム言語(C、Java、Python、アセンブラ言語、表計算ソフト)による出題がなくなり、普遍的・本質的なプログラミング的思考力を問う擬似言語による出題に統一される

シラバス変更箇所表示版(P9)の抜粋
■問題数と解答時間
| 今まで | 2023年4月~ |
|
午前(名前:午前試験) 80問 150分(113秒/問) |
午前(名前:科目A試験) 60問 90分(90秒/問) |
|
午後(名前:午後試験) 11問中5問解答 150分 ※選択問題あり |
午後(名前:科目B試験) 20問中20問解答 100分 ※全問必須 |
■試験の配点及び基準点
ずっと100点満点だと思っていたが1000点満点だったらしい。
まぁ6割必要と思っておいて下さい。

※ 問題ごとの配点割合については、解答結果から評価点を算出する方式のため、具体的に問○が何点ということは明示されていません。
新しい出題方法になるにあたり、IPAのサイト(下部にリンクあります)にサンプル問題が掲載されました。
サンプル問題の解説を作成しましたので是非参考にして下さい。かなりの長文にもなってしまったのでEXCELファイルで公開します。
IPAの通年試験化に関する公表サイト載せておきます。(具体的に知りたい場合はこちらを参照)